
W czasach coraz większej liczby danych prezentowanych bezpośrednio w wynikach wyszukiwania Google, standardowe wyniki organiczne w wielu przypadkach są coraz bardziej spychane na margines uwagi użytkowników. Obecność serwisu w TOP3 nadal pozostaje gwarantem stosunkowo dużego odsetka przejść z wyszukiwarki, jednak zarówno elementy grafu wiedzy, map i newsów, jak również niektóre reklamy Google Ads, zdecydowanie wyróżniają się na tle organicznych, tekstowych wyników wyszukiwania. Paradoksalnie sama obecność na pierwszej stronie wyników Google (w szczególności na dalszych pozycjach) okazuje się często niewystarczająca do skutecznego przyciągnięcia uwagi potencjalnych klientów.
W obliczu walki o wyróżnienie się na tle konkurencji, z pomocą przychodzą tzw. dane strukturalne, które są tematem tego wpisu, a które na przestrzeni ostatnich lat bardzo mocno ewoluowały zmieniając przy tym wygląd wyszukiwarki Google. Poniżej postaram się zaprezentować możliwości oraz korzyści, jakie płyną z wdrożenia tych elementów na różnych typach serwisów.
Czym są dane strukturalne?
Dane strukturalne (nazywane również danymi uporządkowanymi lub rich snippets) to odpowiednio zakodowany w serwisie zestaw informacji, który pozwala robotom wyszukiwarki lepiej zrozumieć zawartość strony. W konsekwencji może przełożyć się to na graficzne wyróżnienie części informacji bezpośrednio w wynikach wyszukiwania. Aby lepiej zrozumieć, na czym polega wyróżnienie, najlepiej posłużmy się przykładem, na którym widać 2 zaindeksowane podstrony z przepisami na ciasto, z których tylko przy pierwszej widoczne są dodatkowe informacje:
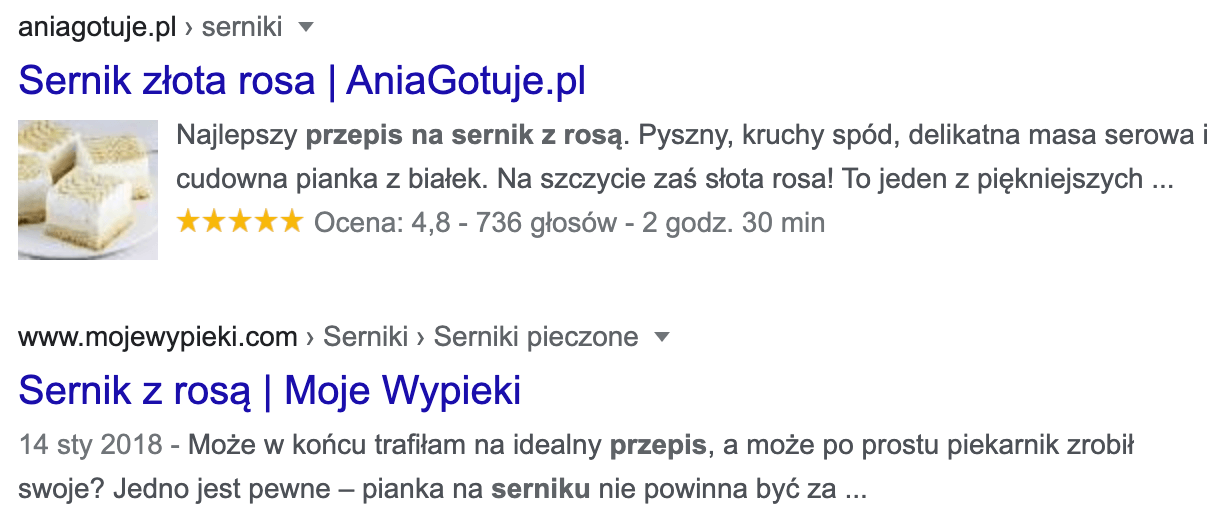
Nie ulega wątpliwości, że taka forma prezentowania informacji podnosi atrakcyjność danego wyniku i istnieje większe prawdopodobieństwo, że przyciągnie on uwagę większej liczby osób. Warto jednak podkreślić, że samo zaimplementowanie odpowiednich rozwiązań w serwisie nie gwarantuje niestety sukcesu, czego najlepszym przykładem jest zobrazowana powyżej sytuacja, w której w obu przypadkach w kodzie dodano np. informację o zdjęciu.
Aby lepiej zrozumieć, jak w praktyce wygląda kod odpowiedzialny za przekazywanie odpowiednich informacji robotom Google, poniżej prezentuję przykład przepisu zaimplementowany poprzez format JSON-LD, który jest rekomendowany przez Google (o innych formatach przeczytasz w dalszej części wpisu):
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Nazwa potrawy",
"author": {
"@type": "Person",
"name": "Jan Kowalski"
},
"datePublished": "2020-09-04",
"image": "zdjecie-potrawy.jpg",
"description": "Opis dania przygotowywanego na bazie przepisu",
"prepTime": "PT20M"
"cookTime": "PT1H"
}
</script>Mimo, że początkowo powyższa struktura może wydawać się problematyczna dla osób, które nigdy nie miały do czynienia z samodzielnym pisaniem lub modyfikacją kodu w serwisie, w dalszej części pokażę, że dodanie danych strukturalnych nie jest wcale takie trudne.
Wpływ danych strukturalnych
Na wstępie warto zaznaczyć, że wdrożenie danych strukturalnych nie wpływa bezpośrednio na pozycje serwisu w wynikach organicznych – a przynajmniej nie ma na to żadnych dowodów. Na przestrzeni ostatnich lat Google kilkukrotnie informowało o tym poprzez swoich pracowników, m.in. Johna Muellera, który w 2018 roku udzielił następującej wypowiedzi na Twitterze:
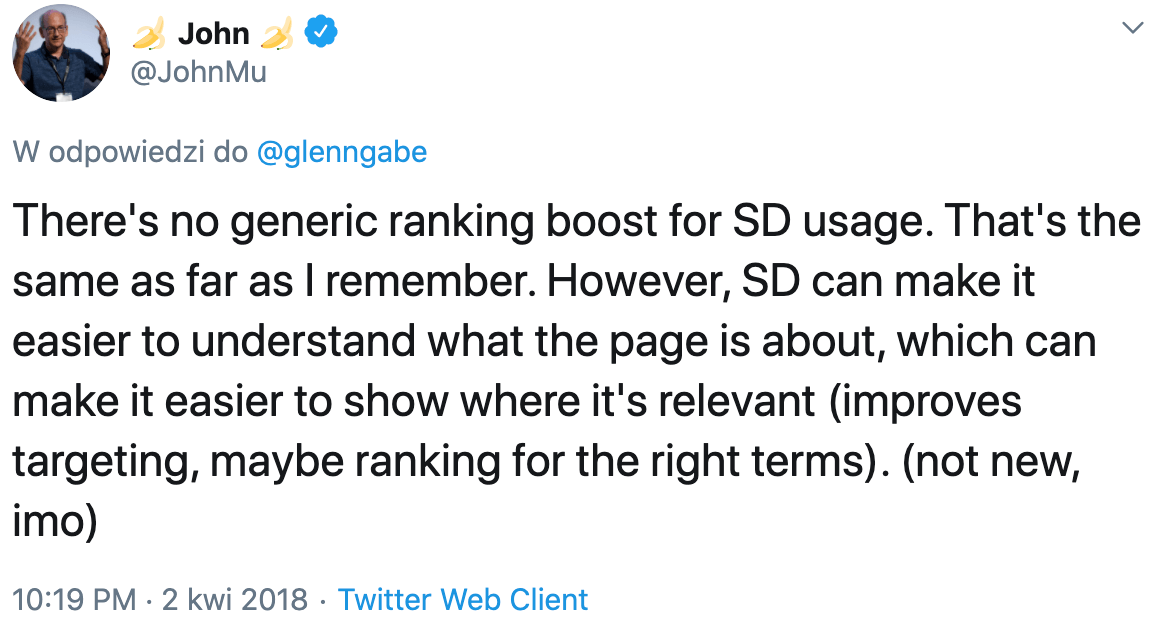
Bazując jednak na wielu opublikowanych testach SEO, można założyć, że w większości sytuacji dodatkowe informacje wyświetlane przy wynikach organicznych zwiększają zainteresowanie użytkowników i tym samym podnoszą CTR (współczynnik klikalności). Co więcej, biorąc pod uwagę stosunkowo niewielkie możliwości wyróżnienia wyników poprzez metaznaczniki <title> i description (w grę wchodzą głównie emoji, których los bywa dość zmienny w kontekście wyświetlania w wynikach wyszukiwania), to właśnie dane strukturalne okazują się najbardziej skuteczną metodą wyróżnienia się oraz „zawłaszczenia” większego obszaru w Google.
O ile procent może wzrosnąć klikalność wyniku, w którym dodano nowe elementy? Podobnie jak w wielu innych kwestiach powiązanych z SEO, najlepszą (i prawdziwą!) odpowiedzią jest „to zależy” 😉 Różnice będą zależały głównie od typu wdrożonych danych strukturalnych, jak również tego, jak często stosowane są one wśród konkurencji. Biorąc za przykład wspomniany wcześniej przepis na ciasto, wszystkie wyniki w TOP3 wyglądają niemal identycznie i ciężko jest tu mówić o jakichkolwiek przewagach konkurencyjnych wyróżniających jeden z serwisów:
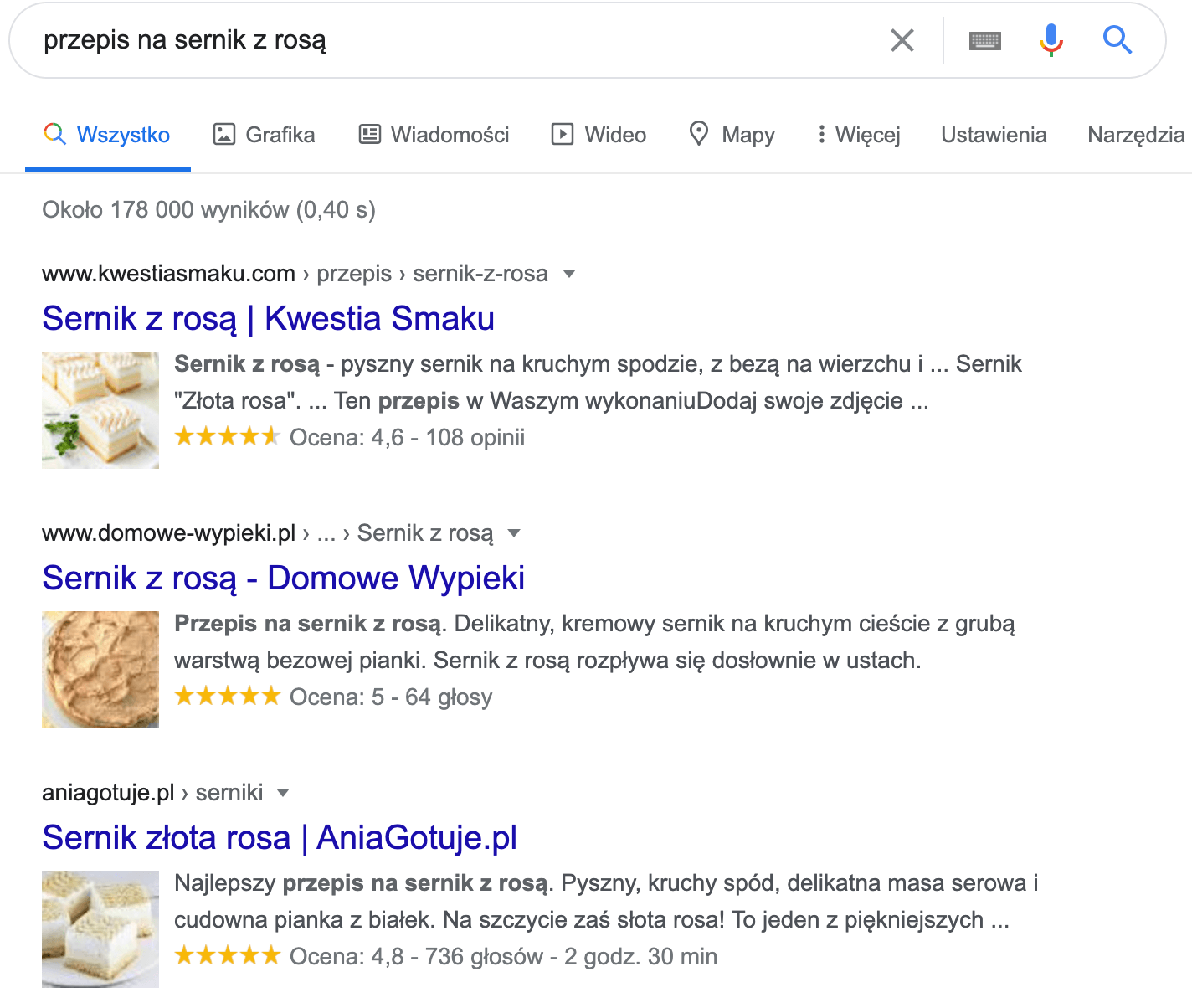
W takiej sytuacji, wdrożenie danych uporządkowanych do wyników, które ich nie mają, nie będzie oznaczało rewolucji w pozyskiwanym ruchu.
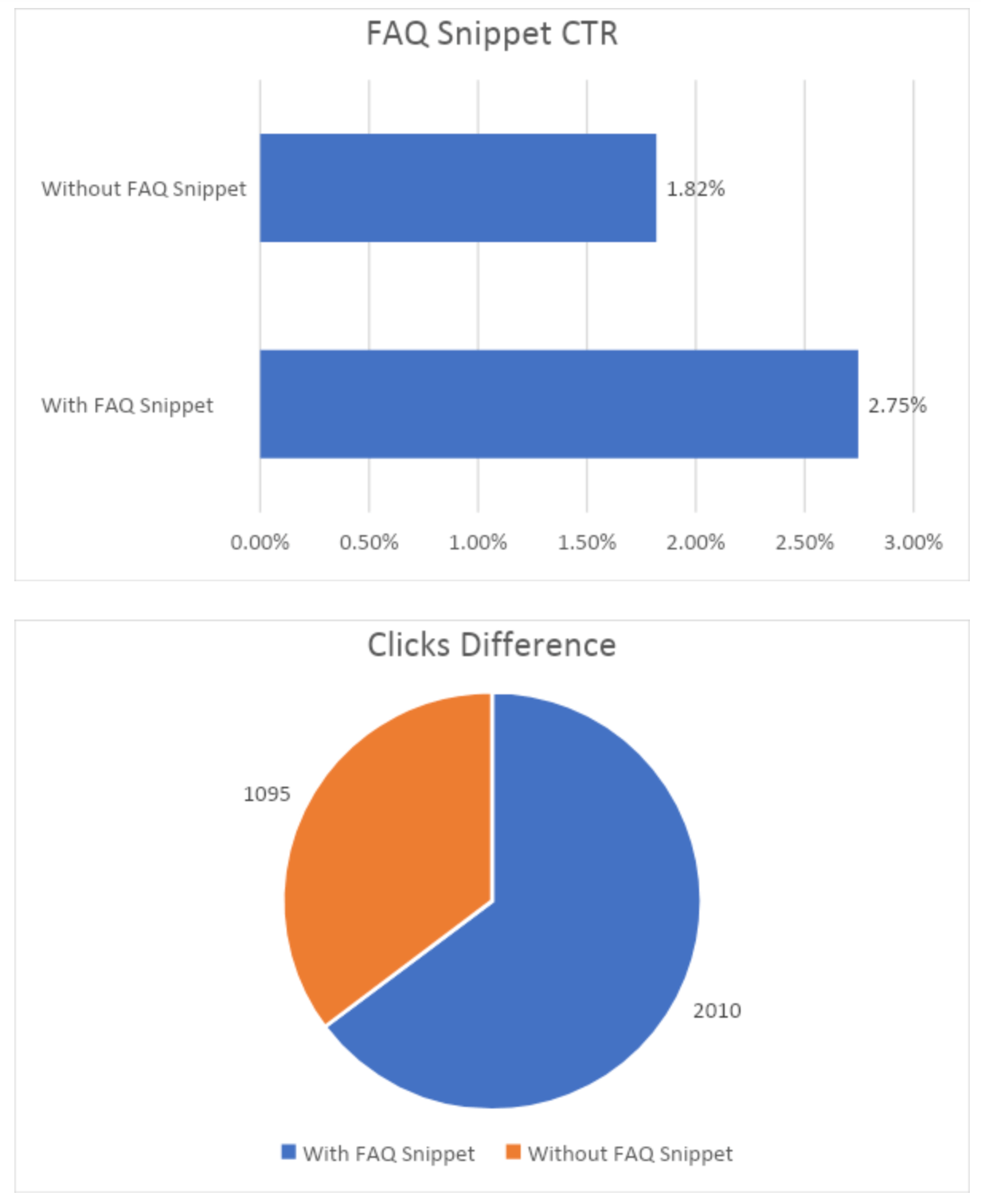
Przykład wzrostu CTR, o którym warto wspomnieć, opublikowany został na Search Engine Land. W opisanym przypadku, na jednej z testowych podstron wdrożono dane strukturalne w postaci FAQ, co zwiększyło CTR z początkowego poziomu 1,82% do 2,75% (około 50% wzrost wartości) i naturalnie dostarczyło serwisowi odpowiedni większy ruch:
Jak zaimplementować dane strukturalne w serwisie?
Aby roboty Google mogły odpowiednio zinterpretować treść serwisu i wyświetlić je w wynikach wyszukiwania w atrakcyjnej dla oka formie, należy te dane w odpowiedni sposób zaimplementować. Warto podkreślić, że Google bazuje na zunifikowanym standardzie danych strukturalnych, utworzonym w ramach projektu Schema.org. Przedstawione na nim schematy podziału poszczególnych typów danych wraz z ich indywidualnymi polami są niemal w całości uznawane przez Google, jednak lepszym pomysłem jest bazowanie na oficjalnej Galerii wyszukiwarki, która daje 100% pewność poprawności wdrażanego kodu.
Obsługiwane przez Google formaty implementacji
Istnieją 3 formaty umieszczenia danych strukturalnych w kodzie serwisu:
- JSON-LD – jest to format zalecany przez Google i stosunkowo najprostszy w implementacji. Całość bazuje na kodzie JavaScript, który powinien zostać umieszczony w sekcji <head> lub <body> i stanowi odrębne „podsumowanie” informacji, które użytkownik może odnaleźć na danej podstronie. W przeciwieństwie do kolejnych formatów, ten format stanowi oddzielny, prosty fragment kodu, który nie musi być zintegrowany bezpośrednio z kodem wyświetlającym informacje na stronie. Poniżej przykład prostego kodu wraz z jego lokalizacją:
<html>
<head>
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Nazwa potrawy",
"author": {
"@type": "Person",
"name": "Jan Kowalski"
},
"image": "zdjecie-potrawy.jpg",
"description": "Opis dania przygotowywanego na bazie przepisu",
"prepTime": "PT20M"
"cookTime": "PT1H"
}
</script>
</head>
<body>
</body>
</html>- Mikrodane – w przeciwieństwie do poprzedniego rozwiązania, mikrodane są reprezentowane przez odpowiednie atrybuty tagów HTML, aby wskazać robotom, który fragment wyświetlanych użytkownikom informacji należy zinterpretować jako dane uporządkowane w ramach pewnego schematu. Implementacja takiego rozwiązania jest o tyle trudniejsza, że wymaga większej ingerencji w kod serwisu oraz potrzebę odnalezienia (a czasem utworzenia) odpowiednich typów informacji w kodzie, a całość jest zdecydowanie mniej czytelna. Poniżej znajduje się kod będący alternatywą dla tych samych informacji zapisanych w poprzednim punkcie:
<html>
<head>
</head>
<body>
<div itemscope itemtype="http://schema.org/Recipe">
<span itemprop="name">Nazwa potrawy</span>
Autor: <span itemprop="author">Jan Kowalski</span>,
<img itemprop="image" src="zdjecie-potrawy.jpg" alt="Nazwa potrawy" />
<span itemprop="description">Opis dania przygotowywanego na bazie przepisu</span>
Czas przygotowania: <meta itemprop="prepTime" content="PT20M">20 minut
Czas gotowania: <meta itemprop="cookTime" content="PT1H">1 godzina
</div>
</body>
</html>- RDFa – bazuje na identycznych założeniach, co mikrodane, a sposób implementacji jest bardzo podobny, co widać poniżej:
<html>
<head>
</head>
<body>
<div vocab="http://schema.org/" typeof="Recipe">
<span property="name">Nazwa potrawy</span>
Autor: <span property="author">Jan Kowalski</span>,
<img property="image" src="zdjecie-potrawy.jpg" alt="Nazwa potrawy" />
<span property="description">Opis dania przygotowywanego na bazie przepisu</span>
Czas przygotowania: <meta property="prepTime" content="PT20M">20 minut
Czas gotowania: <meta property="cookTime" content="PT1H">1 godzina
</div>
</body>
</html>W dalszej części tekstu skupimy się wyłącznie na pierwszym z formatów (JSON-LD), który w większości sytuacji będzie najłatwiejszy w implementacji, a jednocześnie jest on zalecany przez Google.
Jak samodzielnie dodać kod do serwisu?
Zakładając, że nie posiadamy wiedzy i umiejętności umożliwiających samodzielną implementację takiej funkcjonalności w serwisie, a także nie mamy możliwości zaangażowania w to programisty, możliwe jest wypróbowanie 2 alternatywnych sposobów dodania informacji o danych strukturalnych.
Pierwszym ze sposobów jest wykorzystanie do tego celu Google Tag Managera, dzięki któremu na dowolnej podstronie możemy wdrożyć przygotowany przez nas wcześniej fragment kodu. Wdrożenie go w serwisie nie jest trudne, choć – podobnie jak w przypadku Google Analytics – wymaga wklejenia fragmentu kodu (pełna instrukcja dostępna jest tutaj). Po zalogowaniu do GTMa i wybraniu serwisu, na którym chcielibyśmy dodać dane strukturalne, należy dodać nowy tag typu „Niestandardowy kod HTML” wraz z odpowiednią regułą:
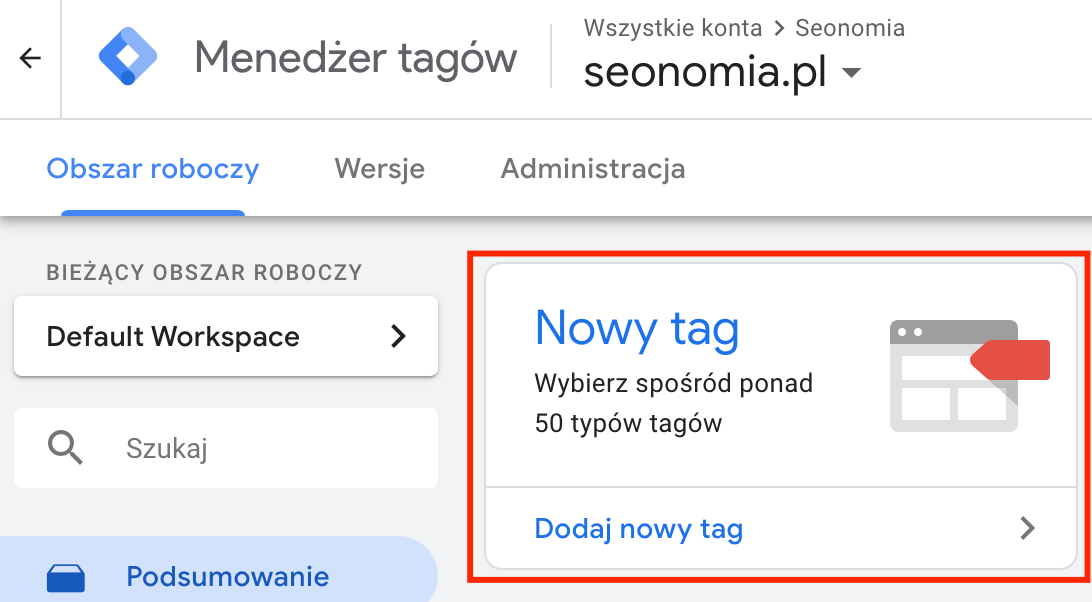
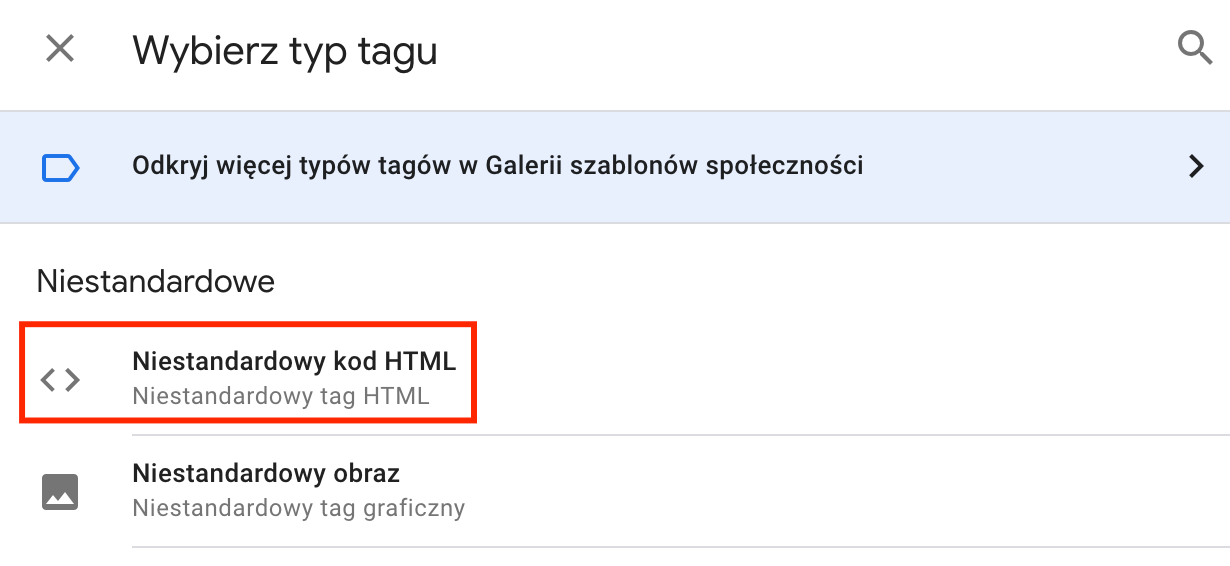
W kolejnym kroku niezbędne jest wklejenie odpowiedniego kodu – można go przygotować samodzielnie na bazie przykładów pokazanych w tym tekście, jednak można również wykorzystać dostępne generatory online, które na podstawie uzupełnianych pól zrobią to za nas. Mając już odpowiedni kod możemy przejść do kolejnych kroków konfigurowania tagu:
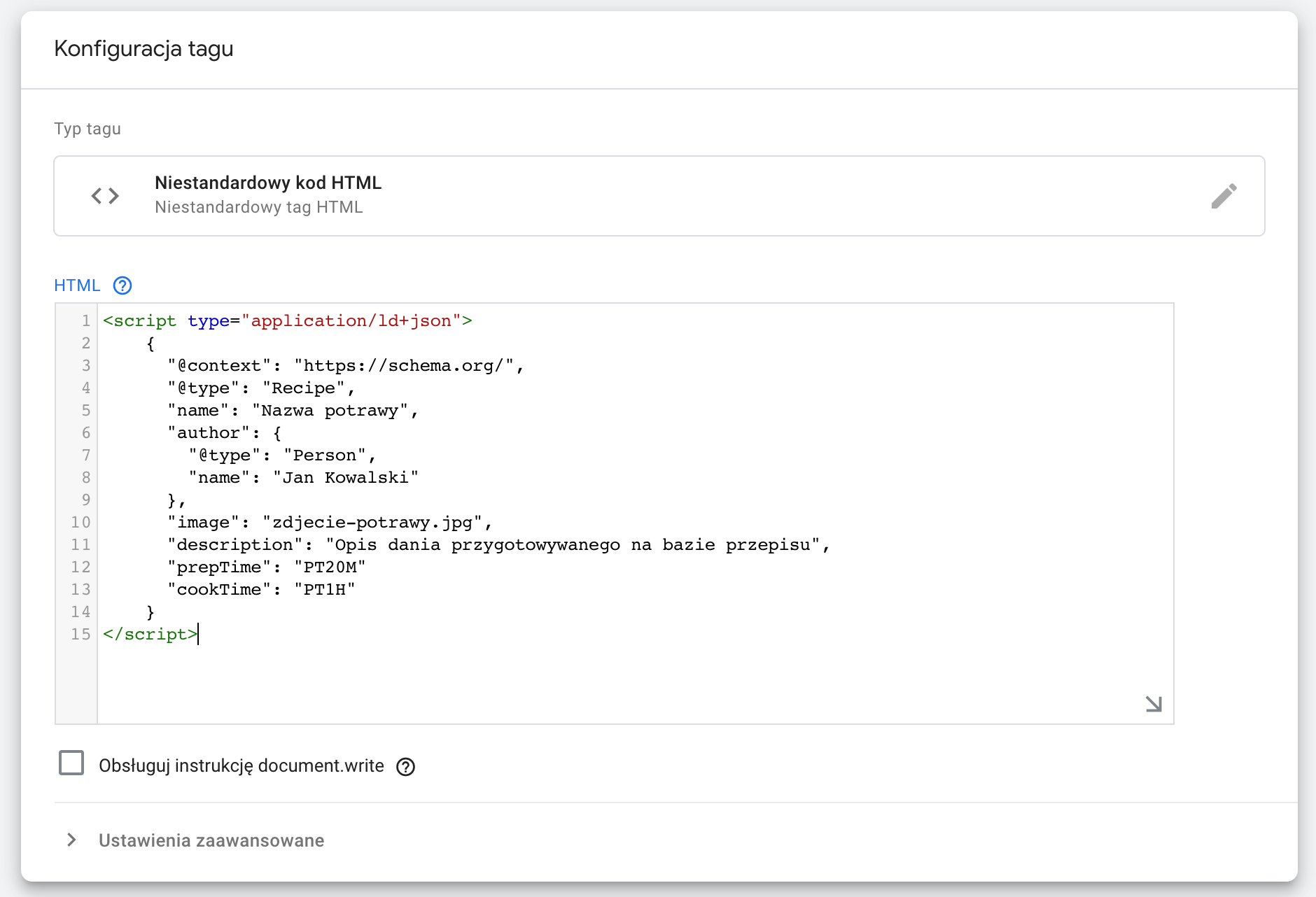
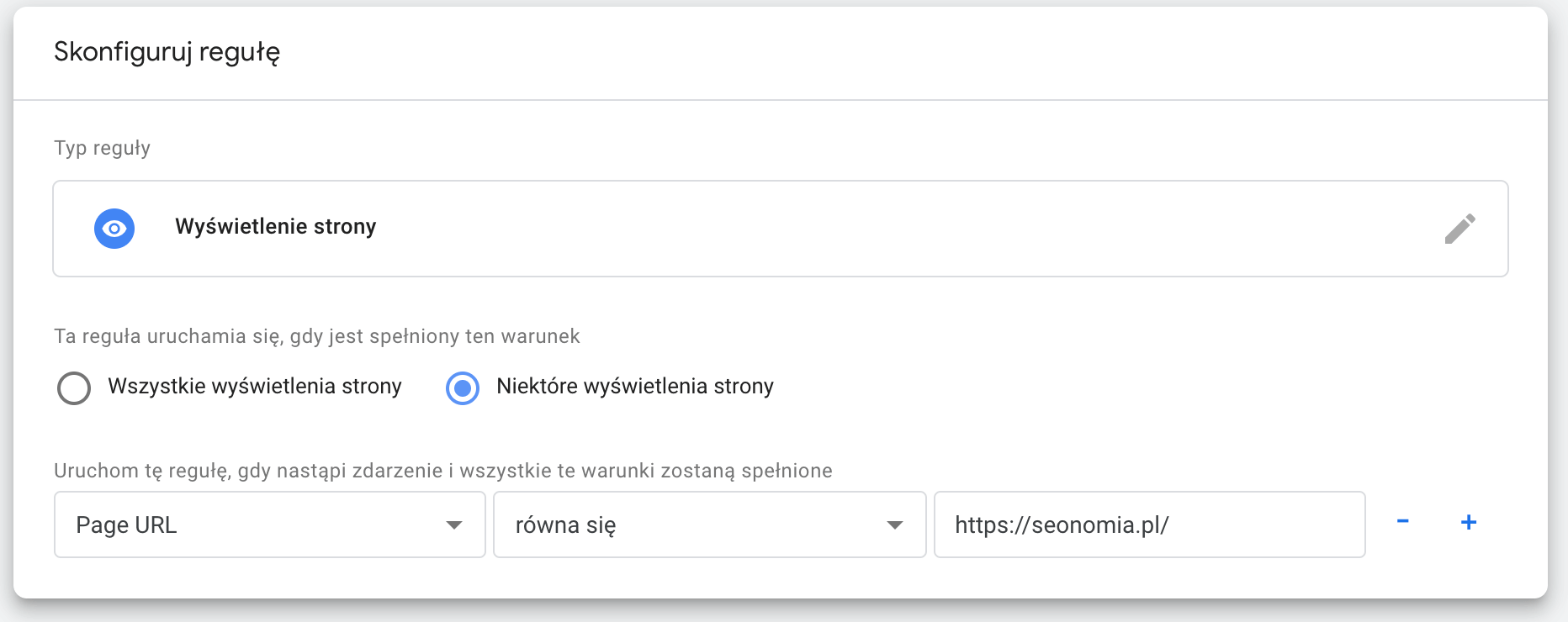
Po opublikowaniu zmian, na wybranej podstronie pojawi się fragment kodu odpowiedzialny za dane strukturalne. Oczywiście jest to ręczna i uciążliwa na dłuższą metę metoda, jednak w przypadku braku możliwości standardowego wdrożenia kodu w serwisie, można to traktować jako alternatywę. Warto również dodać, że GTM umożliwia również automatyzację w zakresie wstawiania danych, co – po odpowiedniej konfiguracji – pozwoli na w pełni zautomatyzowany proces dodawania danych strukturalnych do różnych typów podstron. Więcej informacji na ten temat znajdziesz tutaj.
Jeśli serwis funkcjonuje w ramach platformy WordPress, do dyspozycji jest wiele pluginów, które można w łatwy sposób zainstalować – w przypadku braku funduszy na ten cel, warto zainteresować się RankMath lub Schema & Structured Data for WP & AMP, natomiast dysponując 59$ najczęściej polecanym pluginem jest SNIP, którego obsługa zobrazowana została w poniższym przykładowym nagraniu pokazującym implementację danych strukturalnych dla przepisów:
Jak sprawdzić poprawność kodu?
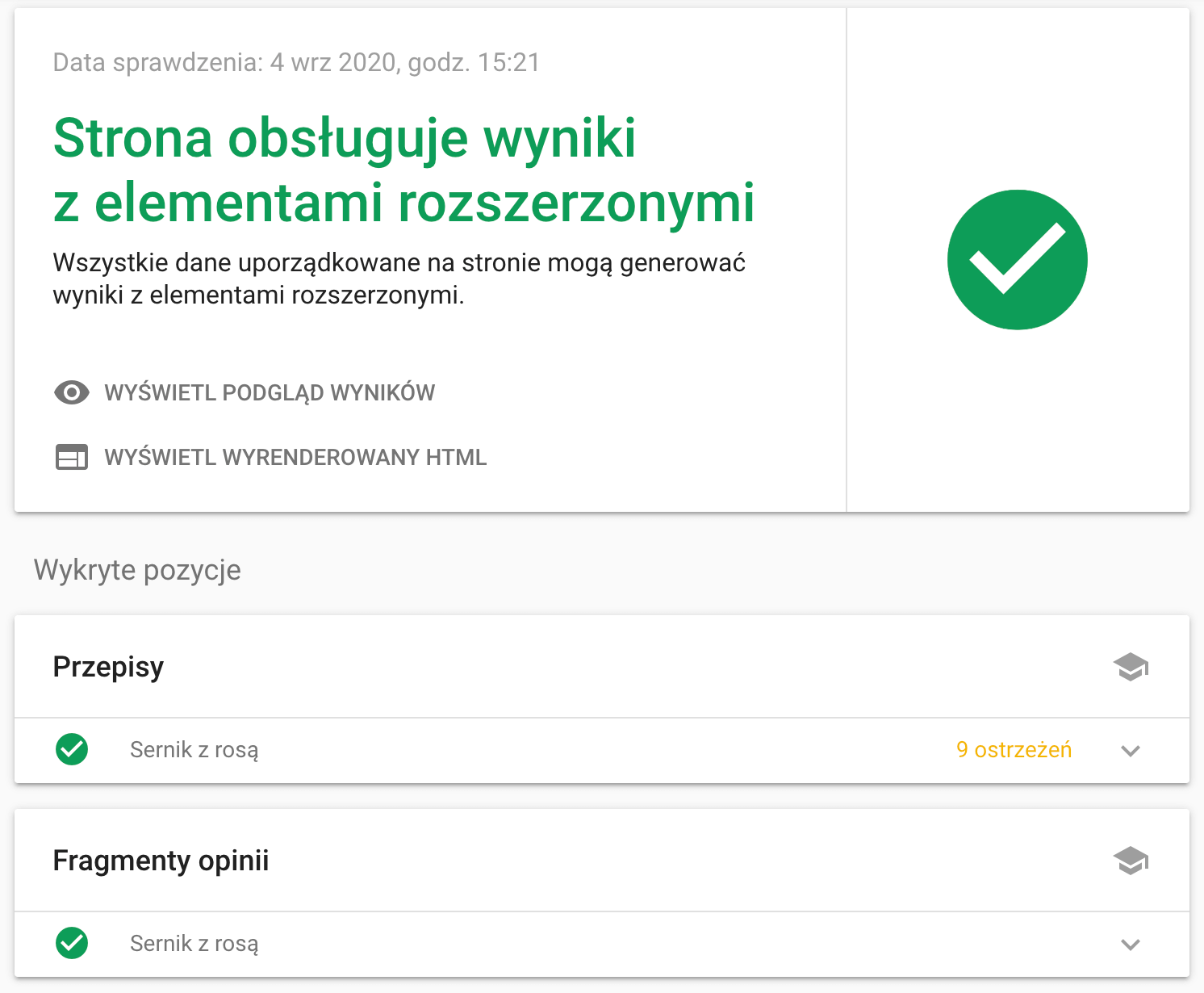
Po opublikowaniu kodu w serwisie, pozostaje nam jedynie sprawdzić, czy Google poprawnie interpretuje dane strukturalne. Cały proces weryfikacji jest na szczęście prosty i sprowadza się do wykorzystania oficjalnego Testu wyników z elementami rozszerzonymi. Przykładowy wynik testu widoczny jest poniżej (warto zwrócić uwagę na dodatkowe informacje o błędach i ostrzeżeniach):
Dodatkowo, po pewnym czasie na koncie Google Search Console pojawią się dodatkowe informacje w sekcji Ulepszenia – w zależności od używanych danych strukturalnych w serwisie, pozycje menu będą się odpowiednio różniły pomiędzy serwisami:
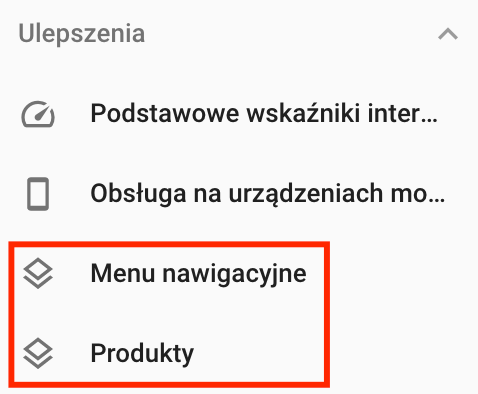
Warto na bieżąco weryfikować poprawność implementacji danych strukturalnych poprzez dane gromadzone przez GSC.
Przykłady danych strukturalnych
Poniżej przedstawionych zostanie kilka wykorzystywanych typów danych strukturalnych, a dodatkowo zachęcam do zapoznania się z pełną galerią wyszukiwarki, w której można znaleźć informacje o wszystkich dostępnych danych w zależności od potrzeb.
Produkty w sklepach internetowych
Link: https://developers.google.com/search/docs/data-types/product?hl=pl
Jeśli serwis oferuje zakup produktów, które dodatkowo posiadają wydzielone podstrony, warto zadbać, aby bezpośrednio w wynikach wyszukiwania pojawiały się dodatkowe informacje, takie jak cena, stan magazynowy, miniatura, ocena i liczba opinii, np.:
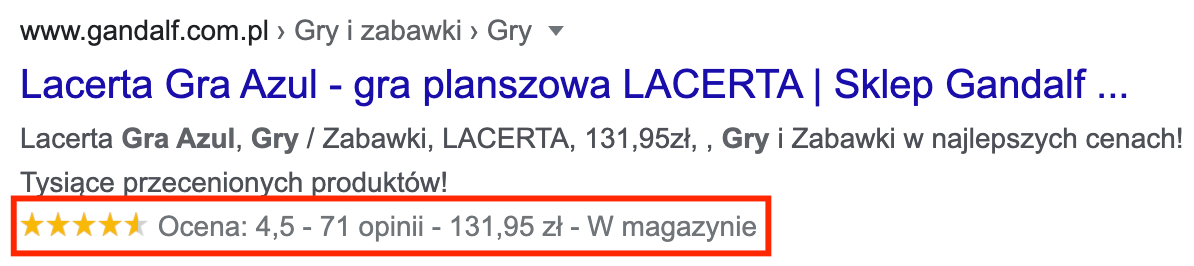
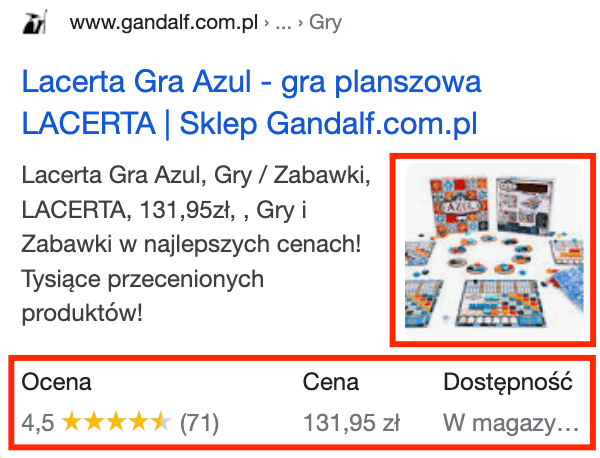
Poza widocznymi powyżej wizualnymi elementami, istnieją również liczne pola, które będą ułatwiały robotom Google lepsze zrozumienie treści podstrony. Poniżej fragment przykładowego kodu nawiązującego do powyższego produktu:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Azul",
"image": "https://www.gandalf.com.pl/o/azul-edycja-polska,pd,843150.jpg",
"description": "Zdobywca prestiżowej nagrody 2018 Mensa Select! Azulejos (...)",
"sku": "843150",
"gtin13" "isbn:5908445421662",
"brand": {
"@type": "Brand",
"name": "Lacerta"
},
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4",
"bestRating": "5"
},
"author": {
"@type": "Person",
"name": "Jan Kowalski"
}
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.5",
"reviewCount": "71"
},
"offers": {
"@type": "Offer",
"priceCurrency": "PLN",
"price": "131.95",
"priceValidUntil": "2020-9-04",
"availability": "https://schema.org/InStock",
"url": "https://www.gandalf.com.pl/p/azul-edycja-polska/"
}
}
</script>Wydarzenia
Link: https://developers.google.com/search/docs/data-types/event?hl=pl
Jest to typ danych szczególnie przydatny dla agregatorów wydarzeń (np. pośredników w sprzedaży biletów na koncerty, czy lokalnych serwisów danej miejscowości), czy też firm organizujących cykliczne wydarzenia (np. szkolenia). Dzięki odpowiedniemu zaimplementowaniu danych uporządkowanych w serwisie, istnieje szansa na wyświetlenie skróconej listy wydarzeń bezpośrednio w wynikach wyszukiwania, a ponadto przy precyzyjnym zapytaniu o dane wydarzenie możliwe jest wyświetlenie się w ramach bezpośredniej odpowiedzi wraz z mapą, co widać na ostatnim z poniższych screenów:
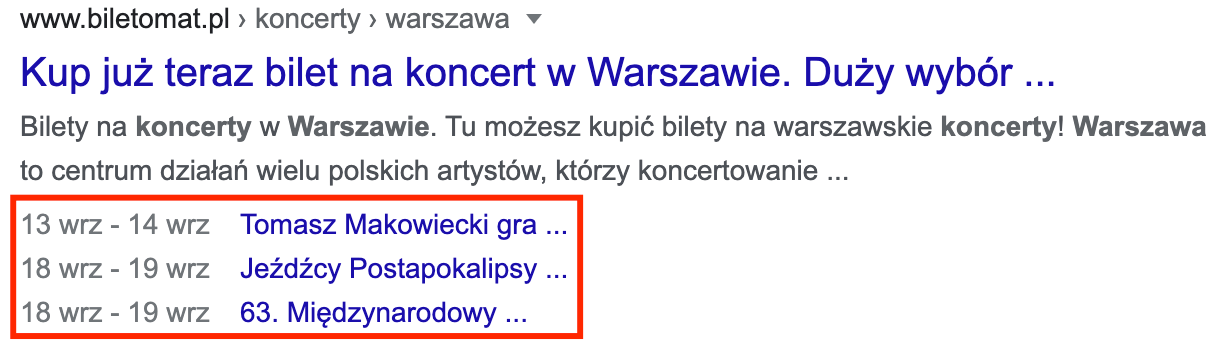
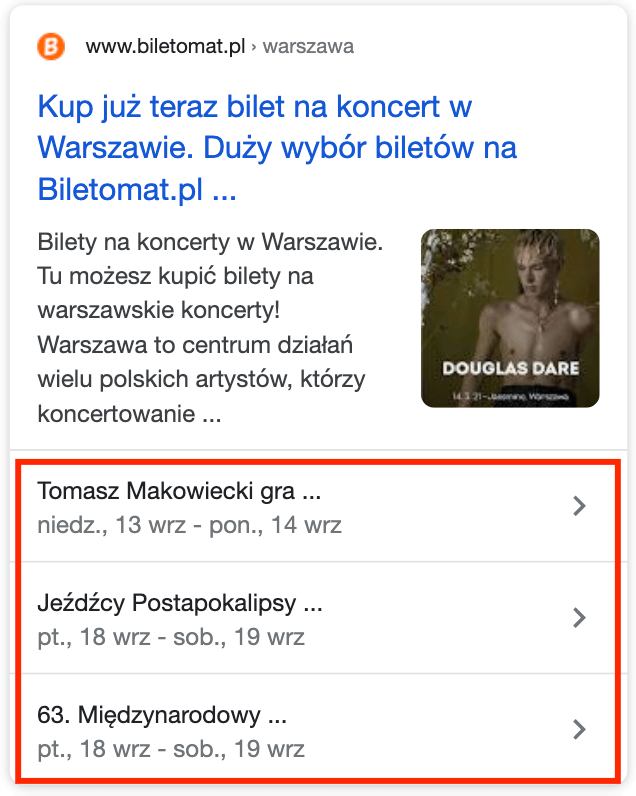
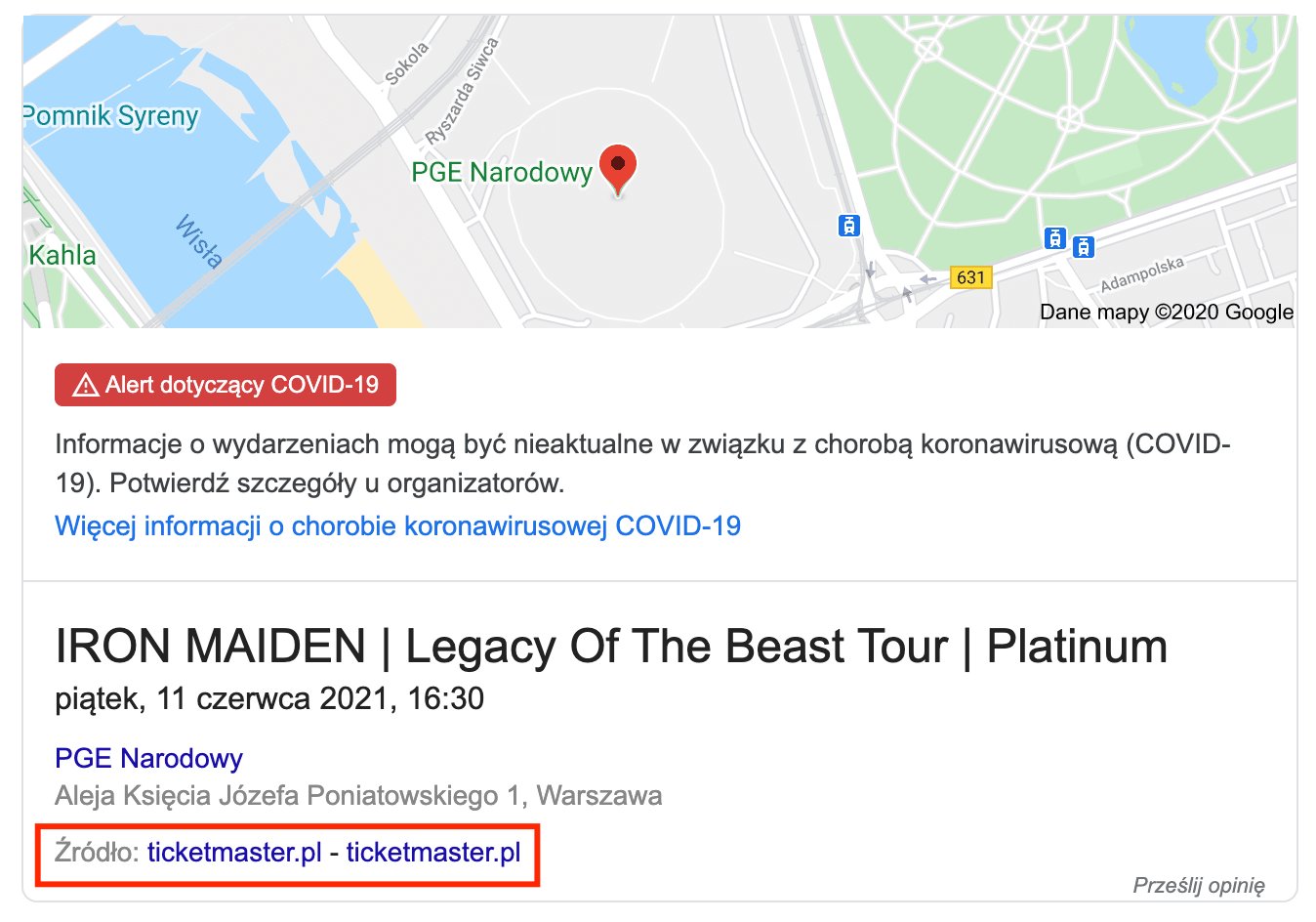
Przykładowy kod odpowiedzialny za dane strukturalne podstrony z konkretnym wydarzeniem:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "MusicEvent",
"name": "Iron Maiden: Legacy Of The Beast Tour",
"startDate": "2021-06-11T16:30",
"endDate": "2021-06-11T22:00",
"eventAttendanceMode": "https://schema.org/OfflineEventAttendanceMode",
"eventStatus": "https://schema.org/EventScheduled",
"location": {
"@type": "Place",
"name": "PGE Narodowy",
"address": {
"@type": "PostalAddress",
"streetAddress": "al. Księcia Józefa Poniatowskiego 1",
"addressLocality": "Warsaw",
"postalCode": "03-901"
}
},
"image": "https://dynamicmedia.livenationinternational.com/Media/j/w/r/d6c7163d-c8be-4017-a900-f6b52092c1a4.jpg",
"description": "Opis koncertu",
"offers": {
"@type": "Offer",
"url": "https://www.livenation.pl/show/1290371/iron-maiden-legacy-of-the-beast-tour/warsaw/2021-06-11/pl",
"price": "179",
"priceCurrency": "PLN",
"availability": "https://schema.org/InStock"
},
"performer": {
"@type": "MusicGroup",
"name": "Iron Maiden"
},
"organizer": {
"@type": "Organization",
"name": "Live Nation Sp. z o.o.",
"url": "https://www.livenation.pl/"
}
}
</script>Najczęstsze pytania (FAQ)
Link: https://developers.google.com/search/docs/data-types/faqpage?hl=pl
Ciekawym rozwiązaniem dla serwisów posiadających stronę z najczęściej zadawanymi pytaniami (FAQ) jest możliwość zaprezentowania części pytań bezpośrednio w wynikach wyszukiwania, co znacząco zwiększa obszar zajmowany przez daną podstronę:
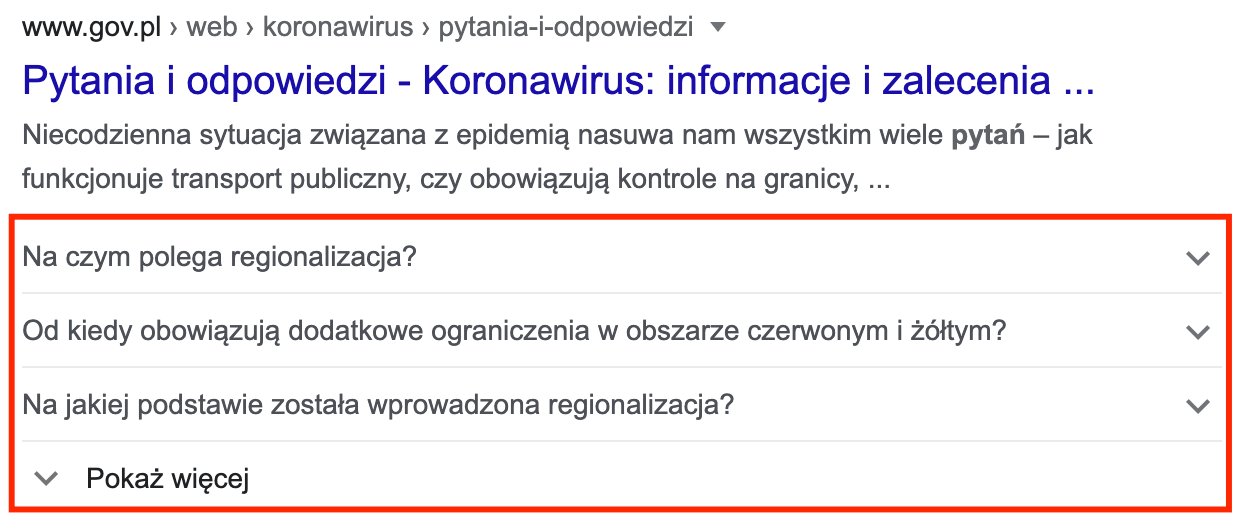
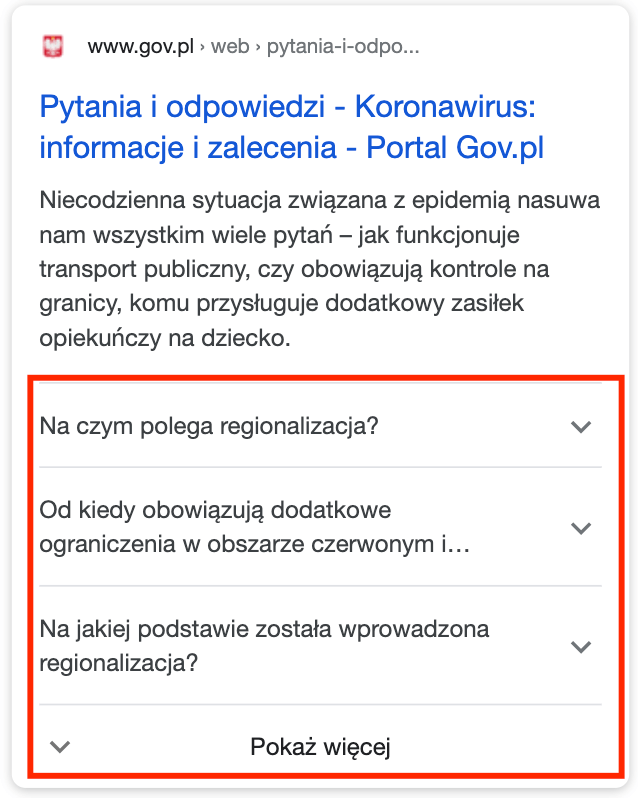
Warto jednak zwrócić uwagę również na fakt, że zastosowanie takiego rozwiązania w niektórych przypadkach może doprowadzić do mniejszej liczby wejść użytkowników, którzy zapoznają się z odpowiedzią na wybrane pytanie już w Google. Poniżej fragment kodu nawiązujący do powyższego przykładu:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Na czym polega regionalizacja?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Regionalizacja polega na wprowadzeniu nowych zasad bezpieczeństwa, ale tylko w poszczególnych powiatach, w których wzrost zakażeń jest większy niż w pozostałych częściach Polski. Powiaty objęte dodatkowymi obostrzeniami dzielą się na dwa obszary: żółty i czerwony – z różnym zakresem ograniczeń."
}
}, {
"@type": "Question",
"name": "Od kiedy obowiązują dodatkowe ograniczenia w obszarze czerwonym i żółtym?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Od 8 sierpnia 2020 r."
}
}, {
"@type": "Question",
"name": "What is the policy for late/non-delivery of items ordered online?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Our local teams work diligently to make sure that your order arrives on time, within our normaldelivery hours of 9AM to 8PM in the recipient's time zone. During busy holiday periods like Christmas, Valentine's and Mother's Day, we may extend our delivery hours before 9AM and after 8PM to ensure that all gifts are delivered on time. If for any reason your gift does not arrive on time, our dedicated Customer Service agents will do everything they can to help successfully resolve your issue. <br/> <p><a href=https://example.com/orders/>Click here</a> to complete the form with your order-related question(s).</p>"
}
}, {
"@type": "Question",
"name": "Na jakiej podstawie została wprowadzona regionalizacja?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Na podstawie Rozporządzenia Rady Ministrów z dnia 7 sierpnia 2020 r. w sprawie ustanowienia określonych ograniczeń, nakazów i zakazów w związku z wystąpieniem stanu epidemii (z późn. zmianami)."
}
}]
}
</script>Podsumowanie
Niemal w każdym serwisie istnieje możliwość dodania odpowiednich danych strukturalnych, które mogą wpłynąć na sposób prezentowania podstron w wynikach wyszukiwania Google oraz lepszą interpretację opublikowanych danych przez roboty wyszukiwarki. Biorąc pod uwagę atrakcyjną formę i realną szansę wyróżnienia się w wynikach wyszukiwania, jest to dobry sposób na osiągnięcie widocznych efektów optymalizacji.